
- Jul 6, 2021
- 12 min read
Written By
- Błażej Fiderek
- Weronika Dranka
- Marek Pasieka
A case study on applying AI to predict the spread of wildfires in South America
Background
Unit8 is committed to dedicating a portion of our working time to pro bono projects. We believe that by applying advanced technology to difficult problems, we can help socially responsible organisations maximise their impact.
Over the past year, we have collaborated with the World Wildlife Fund to help improve the prediction of wildfire spread in South America. In this blog post, the first of a series, we’ll describe how our team leveraged our artificial intelligence (AI) and software expertise to help address a complex and pressing problem.
Our hope is that by illustrating our thought process and project progress, we can provide others with useful insights into the datasets, methods, and an understanding of the state of the art when it comes to problems like modeling wildfires.
This post will cover:
- The threats that wildfires pose in South America
- How we translated the broad problem of wildfires into a more focused technical problem statement
- Useful resources and a quick background on the state of the art when it comes to fire spread prediction technology
- Useful datasets and data science methods for tackling this problem space
Motivation
Wildfires can pose threats to ecosystems throughout the world, but in South America, the effects of deforestation can be particularly severe.
It’s impossible to overstate the global economic and environmental importance of forests. According to one research study, 41 million people worldwide hold jobs dependent on, or related to, the forest sector. At the same time, forest degradation is responsible for 15% of greenhouse gas emissions. That means large wildfires pose severe threats to national economies and climate objectives alike.
After a period of consultation with the WWF, the world’s largest conservation organisation, on where our technology might be most useful, Unit8 began a partnership with the organisation’s Bolivian Branch, WWF Bolivia, and FAN.
WWF Bolivia and FAN are generally able to accurately detect, track, and assess potential wildfire threats in near real time. They have a well-developed network of sensory devices and satellite images that help them identify early threats before they materialise. However, these organisations still face two key vulnerabilities: threats that arise from the unpredicted spread of fire inside the country, and threats that arise from fires that begin beyond Bolivia’s borders, where alerting systems may not be as rapid or accurate.
The danger stemming from unmanaged fire risk is enormous. For example, a devastating fire in 2019 burnt roughly 1 million hectares of forest in San Jose de Chiquitos. As such, organisations like WWF Bolivia and FAN constantly seek to improve their threat-modeling capabilities.
In partnering with WWF Bolivia and FAN, our key objective was to identify and implement technological solutions that could supplement their existing work in the detection, modeling, and elimination of wildfire threats.

Bolivian soldiers managing a forest fire
Problem statement
Presented with the facts described in the previous section, we began our partnership by defining our overarching goal:
“Improve the reaction time in addressing fires that have already started”
Enabling a faster reaction time to a disaster that is already happening seems like a small improvement, but the consequences are significant and meaningful. Even a small advance in delivering information on how fire will spread or enter Bolivia significantly improves fire management capabilities.
Faster reaction times help firefighters prepare for wildfires. They help park rangers decide how best to deal with emerging threats. They allow national leaders to determine the best strategy and pick the right tradeoffs (e.g., which parts of endangered areas should be prioritized). Most importantly, faster reaction times help authorities decide which zones and communities should be evacuated, and when.
After we defined our primary goal, we determined that developing an accurate ML model for predicting fire spread could play a critical role in enabling faster reaction times, as well as identifying the factors that contributed the most to the spread of wildfires or wildfires. That knowledge, in turn, could help alleviate the impact of those factors.
Ultimately, we felt that improving reaction times would be most useful if our solution also provided tools for supporting decision-making. Thus, our two goals were to:
- #1: Improve reaction times in fighting wildfires that had already started
- #2: Provide statistical and visualization tools to support decision-making
We figured that Machine Learning would be an interesting approach for solving Problem #1, but we also knew that the problem needed a more concrete definition. In other words, we needed to narrow the problem to discrete prediction tasks.
After additional research and discussion, our team arrived at three sub-problems where we could apply ML techniques:
- The prediction of the final area affected by a fire
- The prediction of the rate of fire spread
- The prediction of the direction of fire spread
We decided to focus on the latter two. In both cases, a successful solution would need to be able to answer the following: Knowing that a fire has started in a specific location in South America, can we predict where it is going to spread?
The first solution that came to mind was to design and implement an ML solution that could predict which direction of fire propagation was the most probable.
We knew that there are already surprisingly effective predictive models for hurricane path forecasts. However, we also determined that these models wouldn’t be as effective for wildfires. For one thing, wildfires can easily be started by humans, while tornados and hurricanes are purely meteorological phenomena. Moreover, fires are affected by a range of factors, including the presence of human beings, which may contribute to fires ceasing or, alternatively, growing significantly (e.g., when fuel is available). The problem is made even more complex by additional variables like topography and weather.
The dynamics of fire spread are also complex. In fact, a fire might be considered as a collection of separate physical processes. For instance, one factor in wildfires is spotting, which is the non-local creation of fires due to ignition caused by sparks and torches from a primary fire. Ignoring this factor can lead to inaccurate modeling.
We learned about spotting only after conducting extensive research on our own, and it is a good example of how it is essential to develop or account for domain knowledge when choosing the right ML method.
Previous work
As we examined the previous research in this area, we realized that the modeling and understanding of wildfires has made considerable progress in recent years, but still remains far from complete. Most of the successful approaches to modeling wildfires are based on simulation models defined for specific areas and based on local-specific features. As such, these approaches can be hard to generalize.
Below we present a short description of solutions that have already been investigated. Existing research can be grouped into two broad categories:
- Mathematical modeling and simulation
- Machine learning models
Mathematical models usually use a set of non-linear equations that are complex and involve a large amount of parameters. To work on them, specialized knowledge is required. These models are either physics-based or empirical.
Physics-based models are based on the analysis of the physical and chemical processes involved in fires. Two prominent models of this type are Nelson’s (2000) dead fuel moisture model and Albini’s (1979) spotting model which is used to estimate the maximum spotting distance. Nelson’s model is crucial for fire simulation because heat and moisture transfer in dead fuel is strongly related to ignition and fire spread potential. To be usable in practice, theoretical models need to be converted into finite-difference (computer-friendly) numerical ones.
Empirical models are derived from experiments and might be applied only in the environment similar to the one in which they were tested.
There are also models that merge the mentioned approaches. They are called semi-empirical and can simplify mathematical equations that describe physical phenomenons by making assumptions based on a statistical analysis of gathered experimental data. One widely used model in this category is Rothermel’s (1972) surface fire spread model.
The main limitation of these models is that they were very often crafted for specific locations or types of ecosystems. For example, in evaluating past approaches, we found a model for predicting behavior of crown fire designed specifically for Northern Rocky Mountains in the US, a model for predicting dead fuel moisture in Mediterranean areas, and a model for predicting dead fuel moisture in eucalyptus forests.
In short, empirical models and physical models often lack generalizability due to the complex nature of the modeled phenomena (in this case, fires).
Simulations
Wildfire simulations implement mathematical models. They can be thought of in terms of the input data they receive, the output data they produce, and the equations they use to transform the data.
One notable simulator is Farsite. It incorporates most of the fire behavior models described previously into a 2-dimensional fire growth model and is currently available in the FlamMap application.
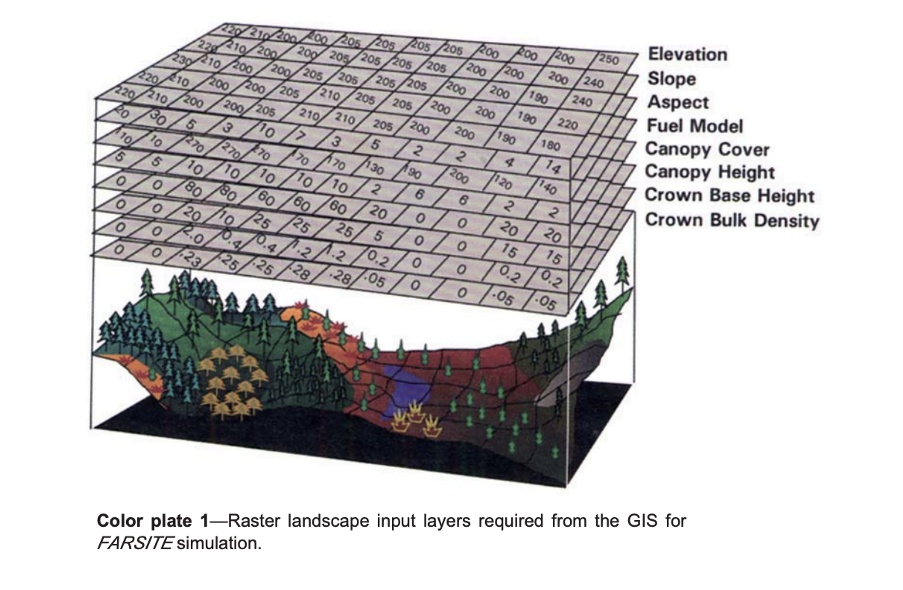
Among other inputs, Farsite uses spatial and tabular data about the landscape, initial fuel moisture, weather, and wind to run fire simulations.
Yet even this highly regarded simulator has its problems. It is necessary to provide reliable input data in certain spatial and temporal resolution to obtain a meaningful output. On top of that, Farsite models can be difficult to calibrate and will not always be applicable, depending on the specific situation.
Finally, Farsite assumes constant environmental conditions, so Farsite simulations become less accurate over time as conditions change in the real world, which leads to the accumulation of modeling errors.
Machine learning models
Machine learning (ML) models rely on data, rather than subject matter expertise. As such, these models may reduce the need for specialised expertise in wildfires.
The ML family of solutions is relatively young compared to mathematical modeling, as the data collection and processing capabilities required for ML solutions were not widely available until recently. This explains why, in recent years, there has been increasing interest in ML applications for wildfire prediction.
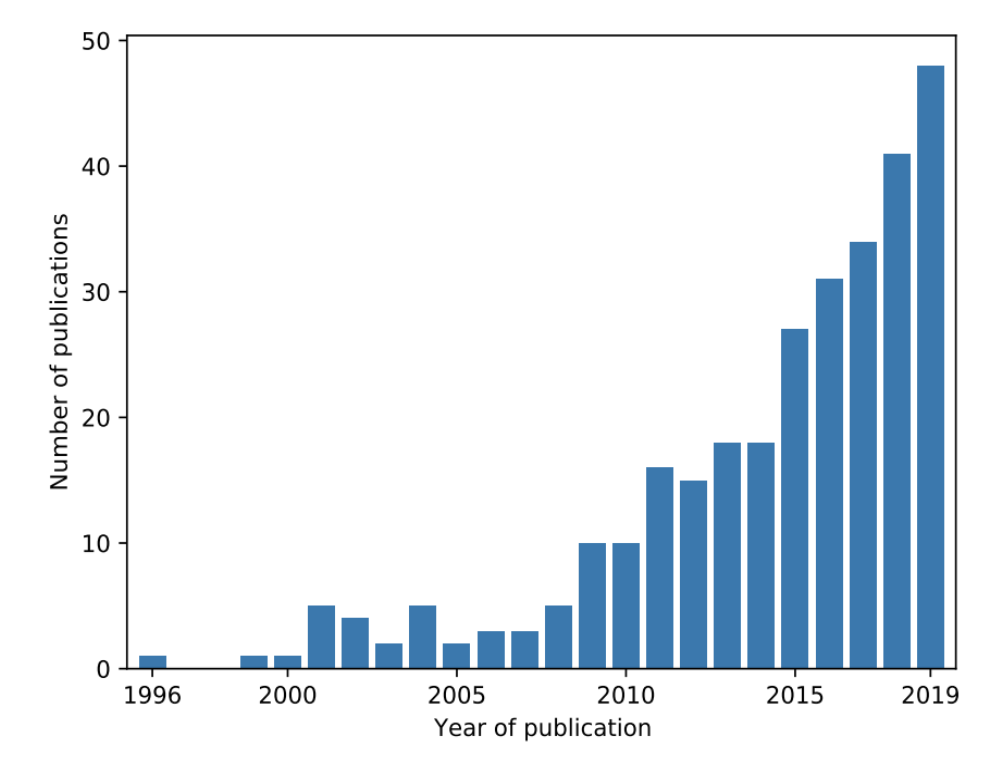
No. of publications by year on the topic of ML and wildfire, source: Piyush et. al 2019
An extensive summary of ML approaches to modeling wildfires shows that, so far, the research is much more focused on descriptive or diagnostic analysis (e.g., fire detection, vulnerability to fire estimation, etc.) and less focused on predicting fire occurrence or behavior. The latter is crucial for effective fire management.
However, the use of remote sensor data and accurate weather forecasts have resulted in several notable ML research projects.
One model worth noting is FireCast, a novel approach in the field that leverages Convolutional Neural Networks to predict fire spread. The algorithm is trained to predict fire perimeter the next day given the current burned area, satellite images prior to ignition, elevation model, and weather variables.
The model takes as an input a grid of pixels and outputs a single value, which is the probability of fire in the next 24 hours in the center of that grid. The model is then trained on the boundaries of the current fire perimeter in order to predict the spread. Because Convolutional Neural Networks require a large amount of data, augmentation techniques are used for replicating training examples.
Importantly, FireCast outperforms Farsite in all tests presented by the authors.
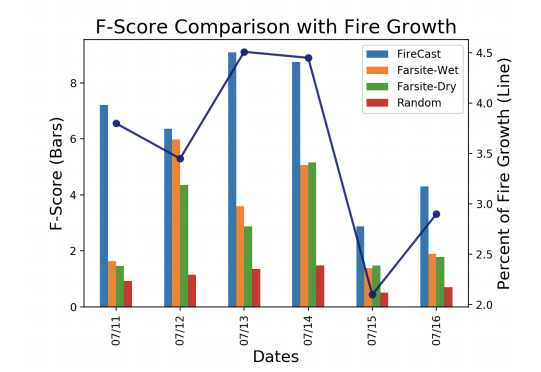
Comparison of FireCast and Farsite in terms of used variables and F-Score. Starred inputs are optional.
Another interesting research attempt was to predict the final area affected by fire in Alaskan’s boreal forests given the location of ignition. In 2019, Coffield et al. used meteorology, vegetation, and topography data to categorize a fire into one of three groups, namely “small”, “medium” and “large.”
The researchers found that the highest accuracy is achieved by the decision tree model with vapor pressure deficit (VPD) and the fraction of spruce cover as features. This model suggests that, at least in Alaska’s microclimate, weather and topography are less responsible for the final fire area. Nevertheless, the top accuracy achieved is 50.4% +- 5.2%,compared to 33.3 +- 4.4% achieved by the random classifier.
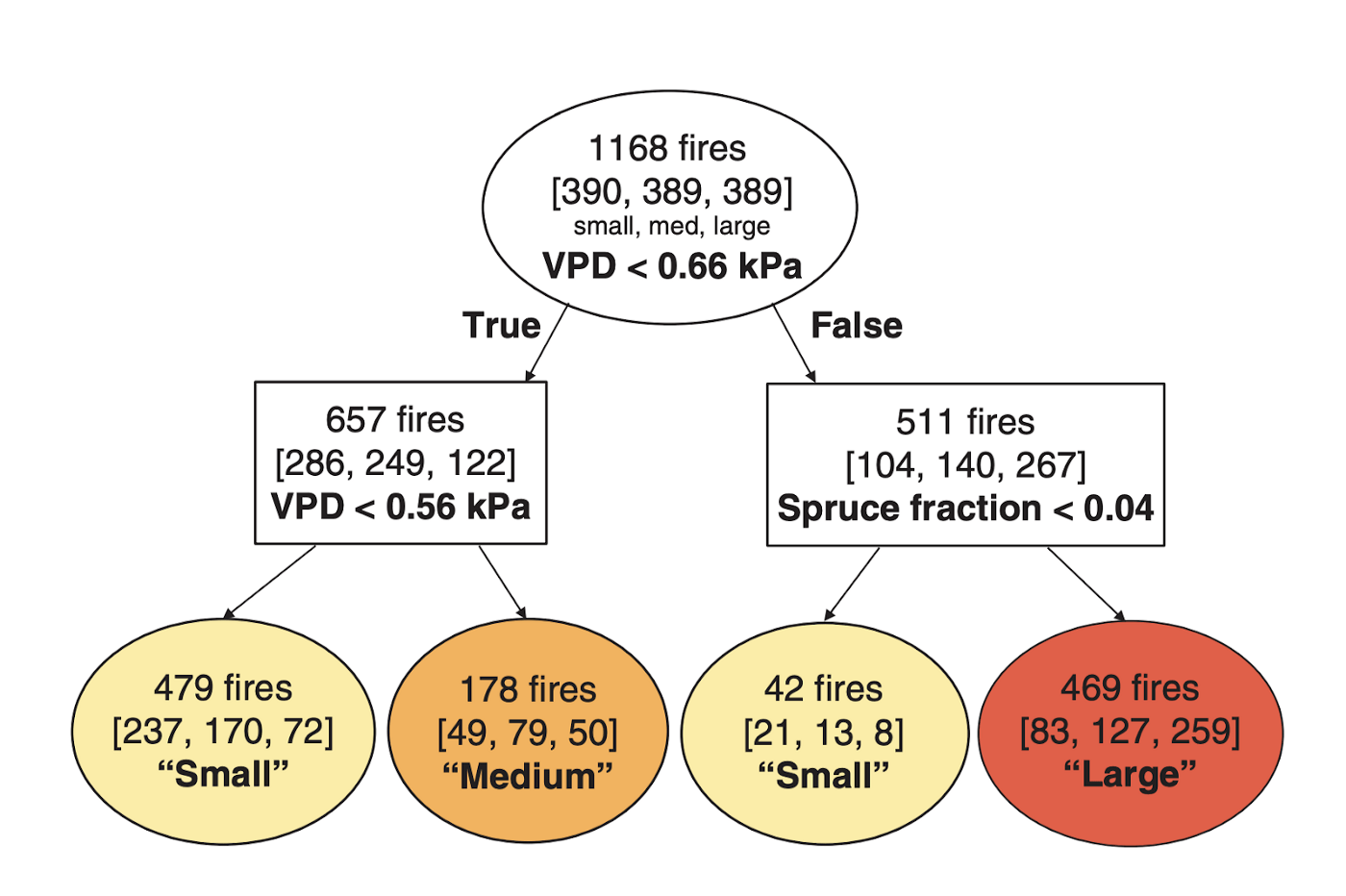
Example of a classification tree with VPD and Spruce fraction as dependent variables.
Datasets
In the majority of research, data preprocessing is one of the most time-consuming phases, which makes it hard to experiment on new datasets efficiently. This problem is exacerbated if the geospatial datasets come from various providers, which is often the case.
Fortunately, there is a platform that solves many of the problems associated with aggregating geospatial data. That platform is the Google Earth Engine (GEE), a cloud-based catalog of satellite imagery and geospatial datasets with many ready-to-use algorithms. GEE is free for research and other non-commercial purposes.
source: https://earthengine.google.com
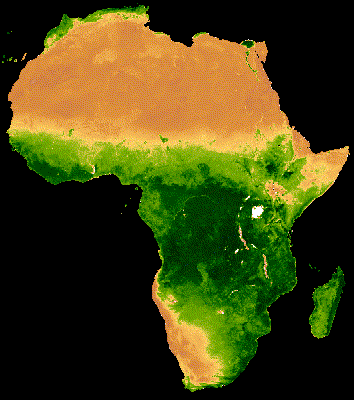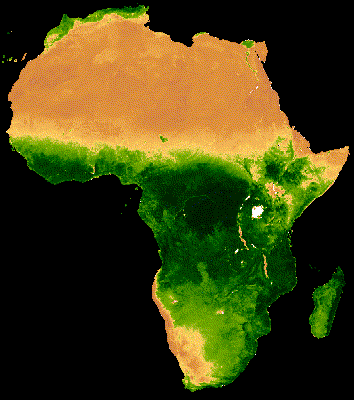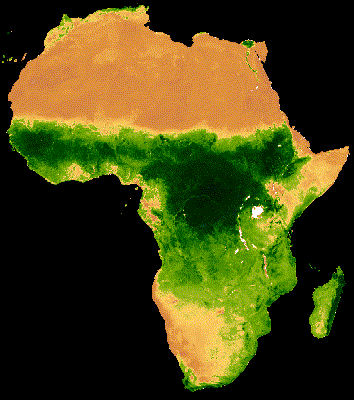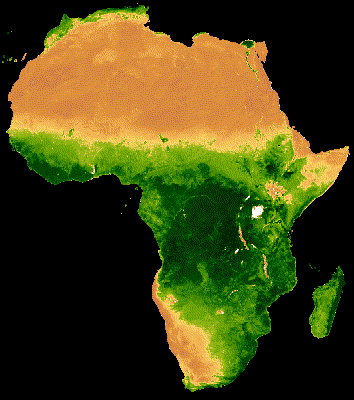
Example of time series visualization of NDVI in Africa using GEE source:https://developers.google.com/earth-engine/tutorials/community/modis-ndvi-time-series-animation
The platform consists of many datasets that can be used for tackling the problem, a few of which are described below.
FIRMS
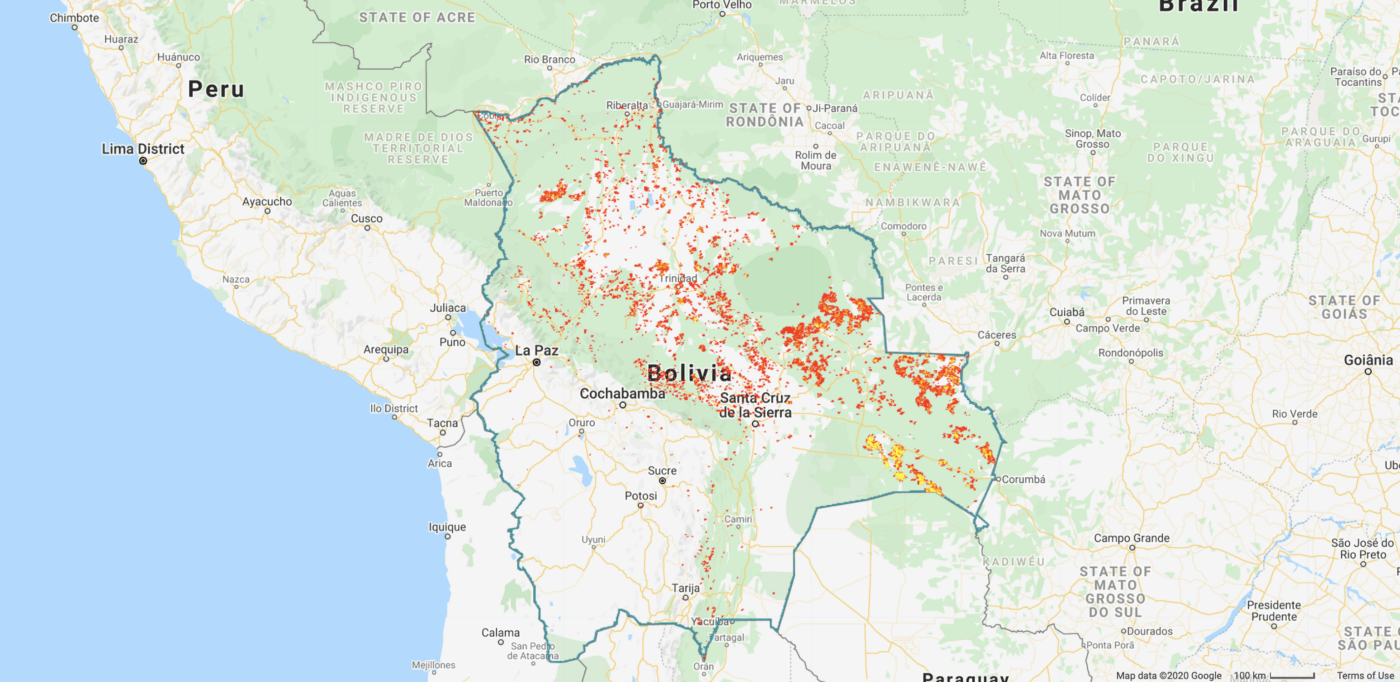
Aggregated fire hot spots in Bolivia, 01 Sep 2019–30 Sep 2019, FIRMS dataset
Spatial resolution: 1km x 1km
Temporal resolution: 24 hours
FIRMS is a global dataset updated in near real time. It contains information about active fire locations and is created from theMODIS MOD14/MYD14 Fire and Thermal Anomalies product. FIRMS consists of two separate layers — one on the temperature of fire and the second on the confidence of fire discovery.
GOES-16 FDCF
Aggregated fire hot spots in Bolivia, 01 Sep 2019–30 Sep 2019, GOES-16 FDCF dataset
Spatial resolution: 2km x 2km
Temporal resolution: 15 minute
GOES-16 FDCF is a dataset provided by NOAA and derived from the geostationary satellite GOES-16. This dataset covers North and South America and produces active fire hot spots every 15 minutes. In addition, it provides sub-pixel fire characteristics, such as the area of afire.
FireCCI51
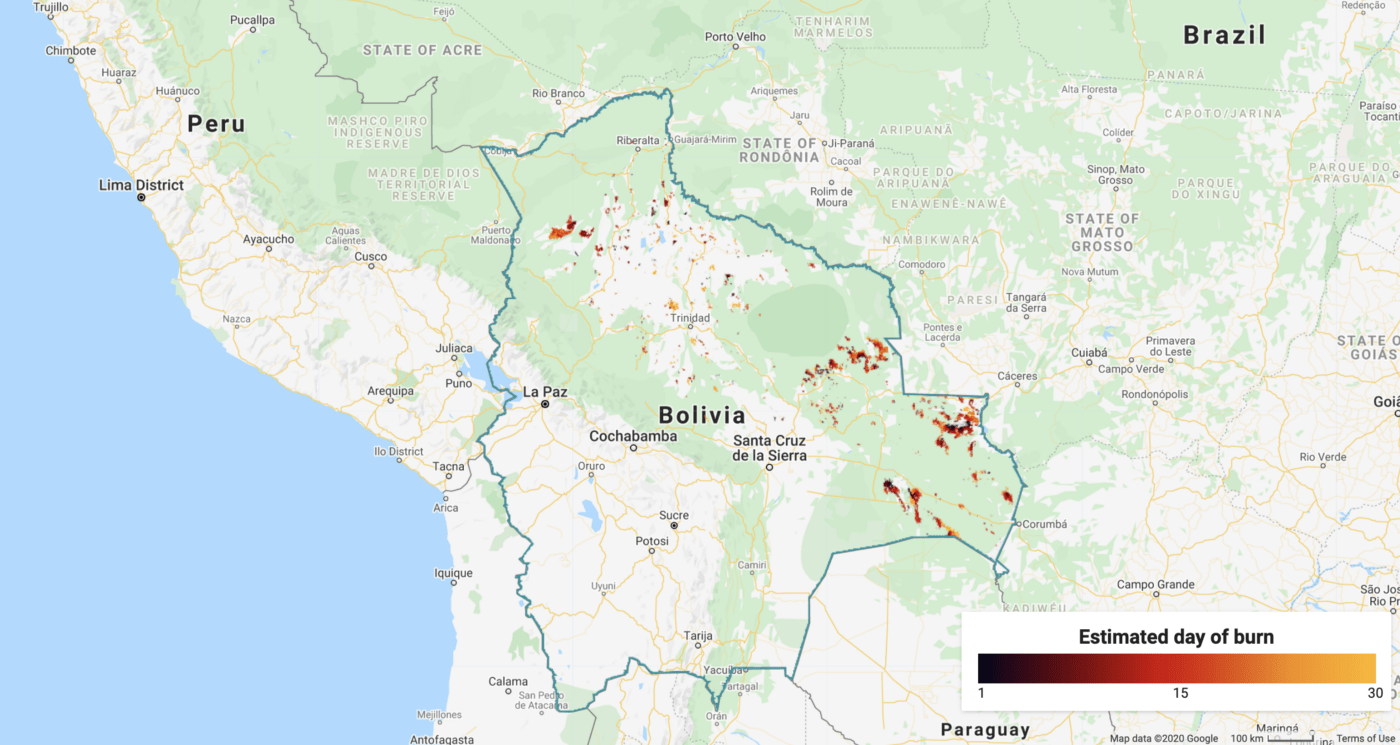
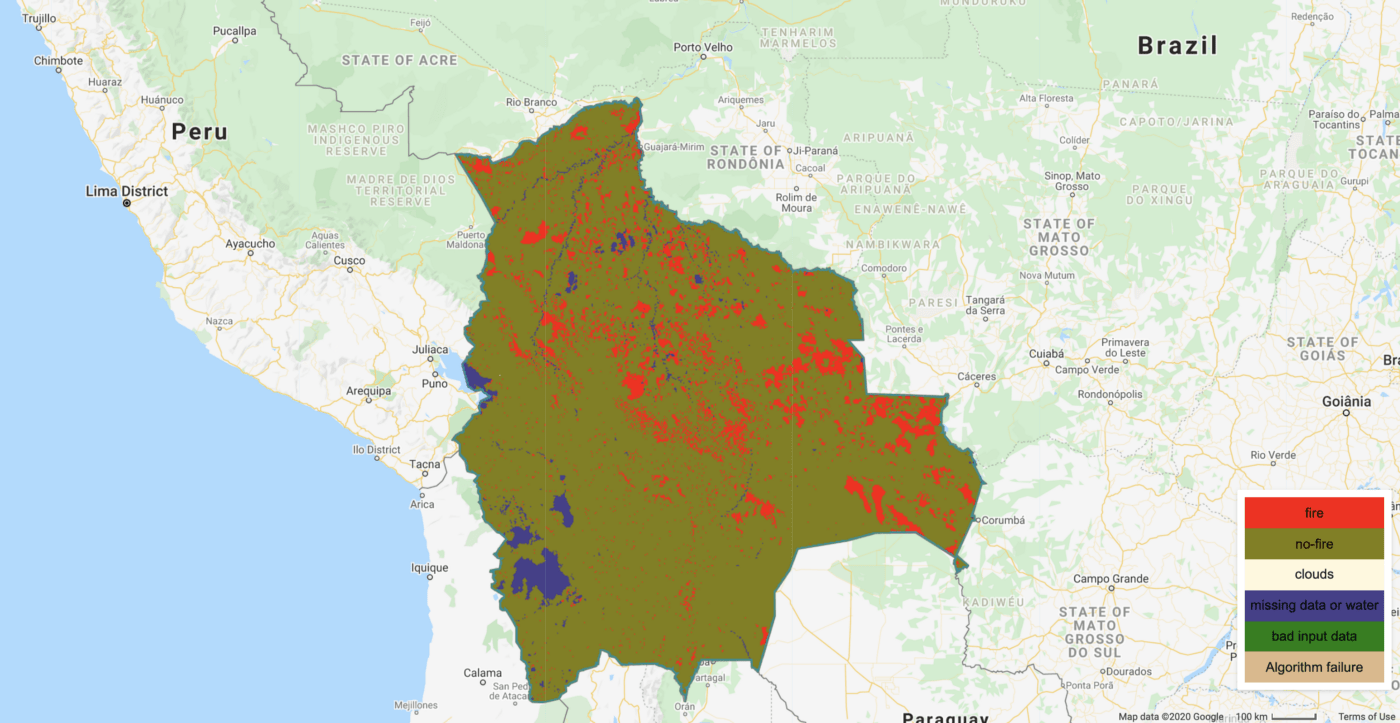
Burned pixels in Bolivia, 01 Sep 2019–30 Sep 2019, FireCCI551 dataset
Spatial resolution: 250m x 250m
Temporal resolution: 1 month
The FireCCI burned area pixel product is a global dataset based on surface reflectance data from MODIS Terra and Aqua satellites provided by the European Space Agency.
The main advantage of FireCCI over the previous datasets is that it mostly consists of areas (clusters of pixels) instead of sparse fire hot spots, which is achieved by means of a two-stage algorithm.
Although the dataset’s resolution is monthly, it contains a layer with an estimated day of the burn. Another example of a similar dataset is MODIS Burned Area Monthly dataset.
So far we have discussed datasets with fire layers, but GEE has also many products that can serve as dependent variables. Some examples are the Global Forecast System, SRTM Digital Elevation Model, and EVI datasets.
To help researchers and others familiarize themselves with these datasets, we have developed two applications on top of Google Earth Engine that we would like to share with community.
These applications make use of the aforementioned GOES-16 and FireCCI551 datasets and allow users to observe fire history and calculate some informative statistics. Our applications are easy to extend and can be modified to handle other datasets and features. Because the GOES-16 dataset is updated on a daily basis, our application can serve as fire monitoring tool.
Summary
Fire spread prediction is an important problem that can be tackled in many different ways. The complexity of fire behaviour suggests that leveraging Machine Learning can result in a more successful predictor than has previously been available.
While we know that this level of performance is not an easily achievable target—especially when previous modeling attempts have used local-specific data in high resolution — we believe that the growing number of available datasets, resources and tools makes it easier for researchers today to focus on the heart of the problem, rather than technical dependencies or setup.
In AI for Good — Unit8 for WWF pt. 2, we discuss the challenges of modeling wildfires with the ML approach, share our lessons learned, and outline the results of our research.
Thanks to Weronika Dranka.

