
- May 19, 2021
- 10 min read
Written By
- Radu Jica
At Unit8, we work with our clients to help them tackle challenges and envision new ways to leverage technology in how they do business. In order to achieve that, they entrust us with their data and hope that we will turn it into value. Unfortunately, very often the client data that we work with is distributed across multiple systems and/or suffers from severe quality issues. One technique that enables us to deal with this kind of problems is Entity Resolution. This article is the first of an in-depth series that will cover theoretical as well as practical aspects and challenges in real-life applications.
Entity resolution is about determining whether records from different data sources represent, in fact, the same entity. In order to better understand what the process entails and why it might be relevant to you, let’s take a look at a couple scenarios.
Now, imagine your company has clients all around the world. You would like to get the answer to a simple question: how many clients do I have? Easy, you might say, let’s look in this database and count; which might work just fine! Unless you started keeping this information in paper documents long before digital systems arrived or perhaps you are simply storing the data in separate places, depending on location. There might not be a unique identifier across all data sources, nor any guarantee that there are no duplicates. Even after aggregating everything in one place, such a question remains: is John Doe with an account on Youtube the same John Doe with a Google account? This is a question which Google was trying to answer when acquiring Youtube. A global store like Amazon might similarly want to find out how many unique products they sell, when so many are in fact the same but listed under different suppliers.
Ok, but why does it matter so much? Let’s imagine that you’re in the business where consistence of your data is the key. Your question is: do I have any client trying to commit fraud? Am I able to detect if someone is trying to avoid paying taxes, sharing foreign incomes or just presenting inconsistent personal data, such as nationality or address? Inability to do so has led to major public scandals, the banking industry being one such case.
Imagine that Waldo desperately needs money to start a new business. He decides to apply for a loan at a local bank with his Swiss passport and everything goes well. Waldo however still needs some money to keep his new business going and another loan will not be approved. Interestingly though, Waldo, like 25% of Swiss citizens, has dual nationality. He successfully manages to get another loan in a different branch of the same bank using his Austrian passport. His fraudulent behaviour could go undetected if the banks assume the equivalence of one passport to one person and vice versa. Situations like these have graced headlines in press for years and range from financial fraud to rigged votings.
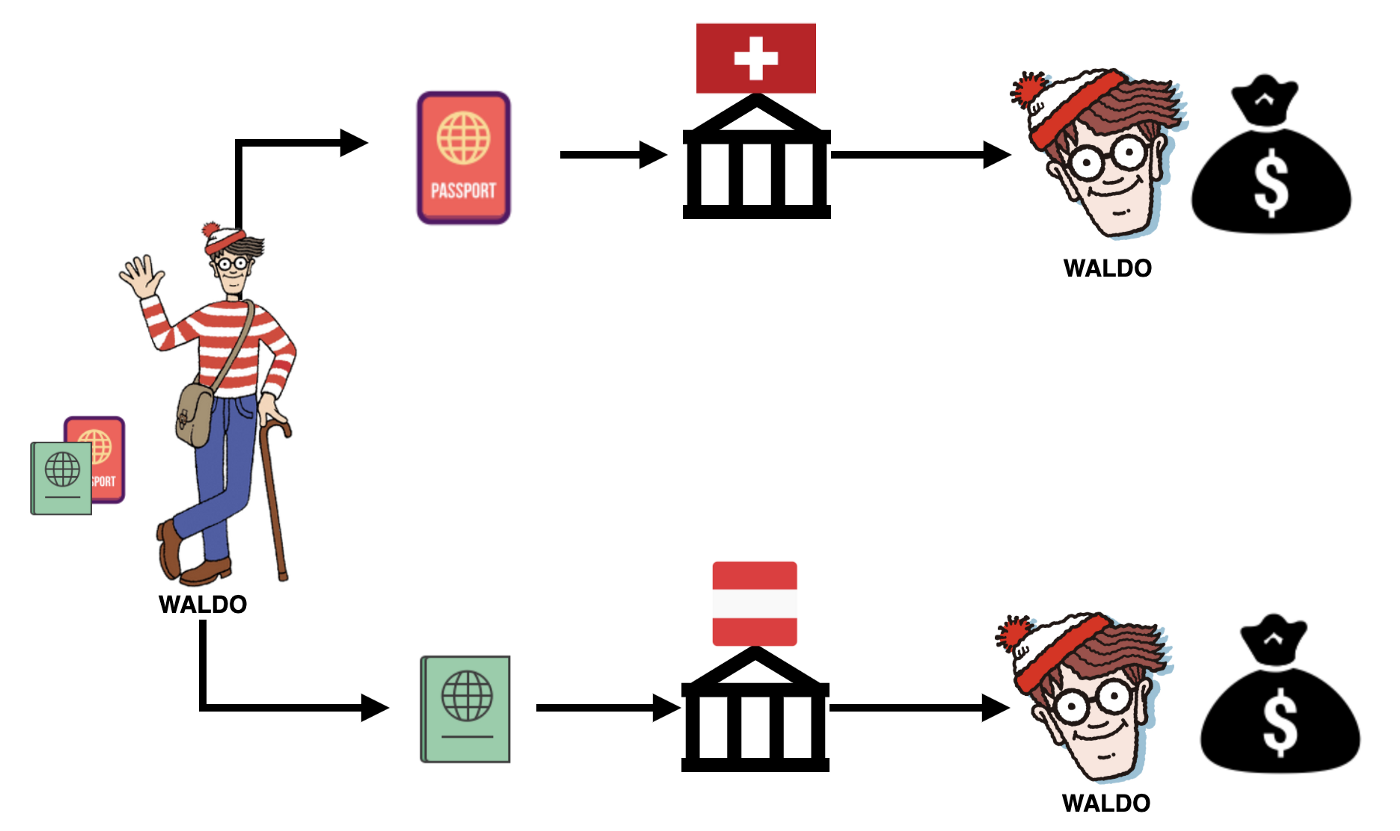
For example, HSBC was fined $1.9 billion in 2012 for failure to prevent money laundering by Latin American drug cartels. Another example is BNP Paribas, fined for $8.9 billion in 2015 for violating sanctions against Sudan, Cuba and Iran. Hence, not being able to find these kind of connections can lead to serious financial and reputation repercussions. Such high-profile cases led to more companies adopting entity resolution as part of their business processes.
OK, I’m convinced; so how do you do it?
Essentially, what we need to do is to find out if multiple records (i.e. rows in tabular data) refer to the same entity. This process is called Entity Resolution, or alternatively Record Linking, Deduplication, or Data Matching (depending on the domain).
There are some typical steps involved, as depicted in the following diagram. Note that this process might differ, depending on the use case. One starts by gathering all the available datasources, combining the records into a single format, and cleaning them. Afterwards, the actual entity resolution magic begins by creating all the possible pairs through a process called blocking. This is an essential step, because it drastically reduces the computational cost, as we’ll later see. Only then you can start matching them according to certain rules or model predictions. This results in a bunch of edges from which similar entities are extracted, giving us the so-called clusters.
For the remainder of this post, we’ll go a bit deeper into each step while following an example. For the purpose of this post, we are entity resolving people, but the same process could be used in other domains.
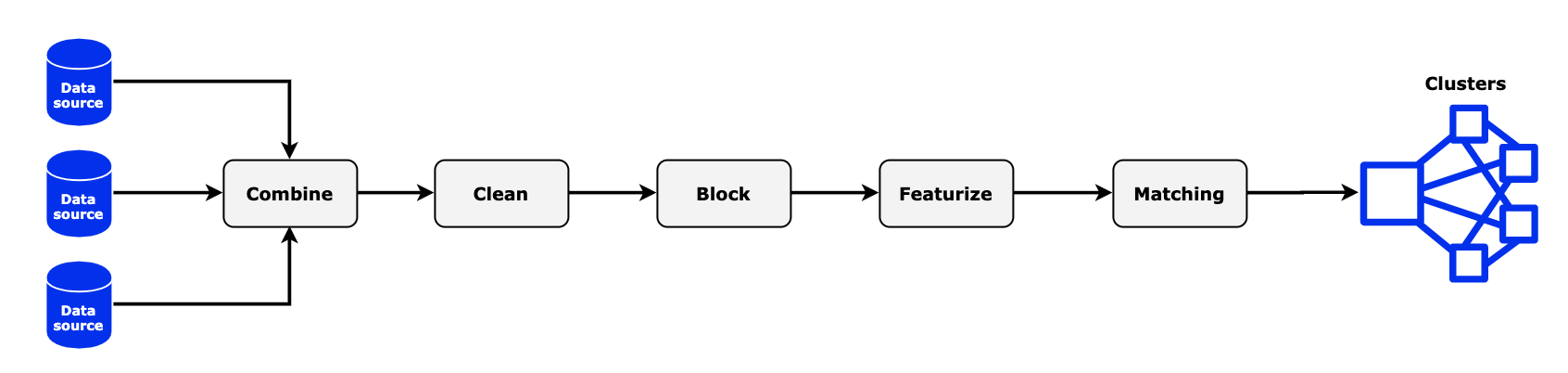
Entity Resolution Steps
Combine
The first step is getting all the data and combining it into a common schema. In a perfect world, there would be one global database containing all the data in a single schema. In practice however, there are usually multiple datasets stored in various systems and formats. There might be a relational database to store clients of a shop and a NoSQL for their reviews of products; these could be duplicated between countries or overlap. There could also be a legacy system which is not yet decommissioned and can only return one row at a time in some obscure format. Though cumbersome, centralising the data across multiple sources is essential.
The remaining challenge is deciding on a common schema. Which fields are relevant? Do we need to know in which country is John Doe born? Is it relevant that he’s a foreigner? Is his birthday actually a date type? After answering these questions and combining the data, one can finally continue with the next steps.
Let’s say we have two data sources that store clients of a company across different branches. Each branch has their own database and schema. Notice how, after combination, the source columns have been selected, mapped appropriately and to the right data type. Also observe how the column nationality, deemed irrelevant, was removed from the resulting table.
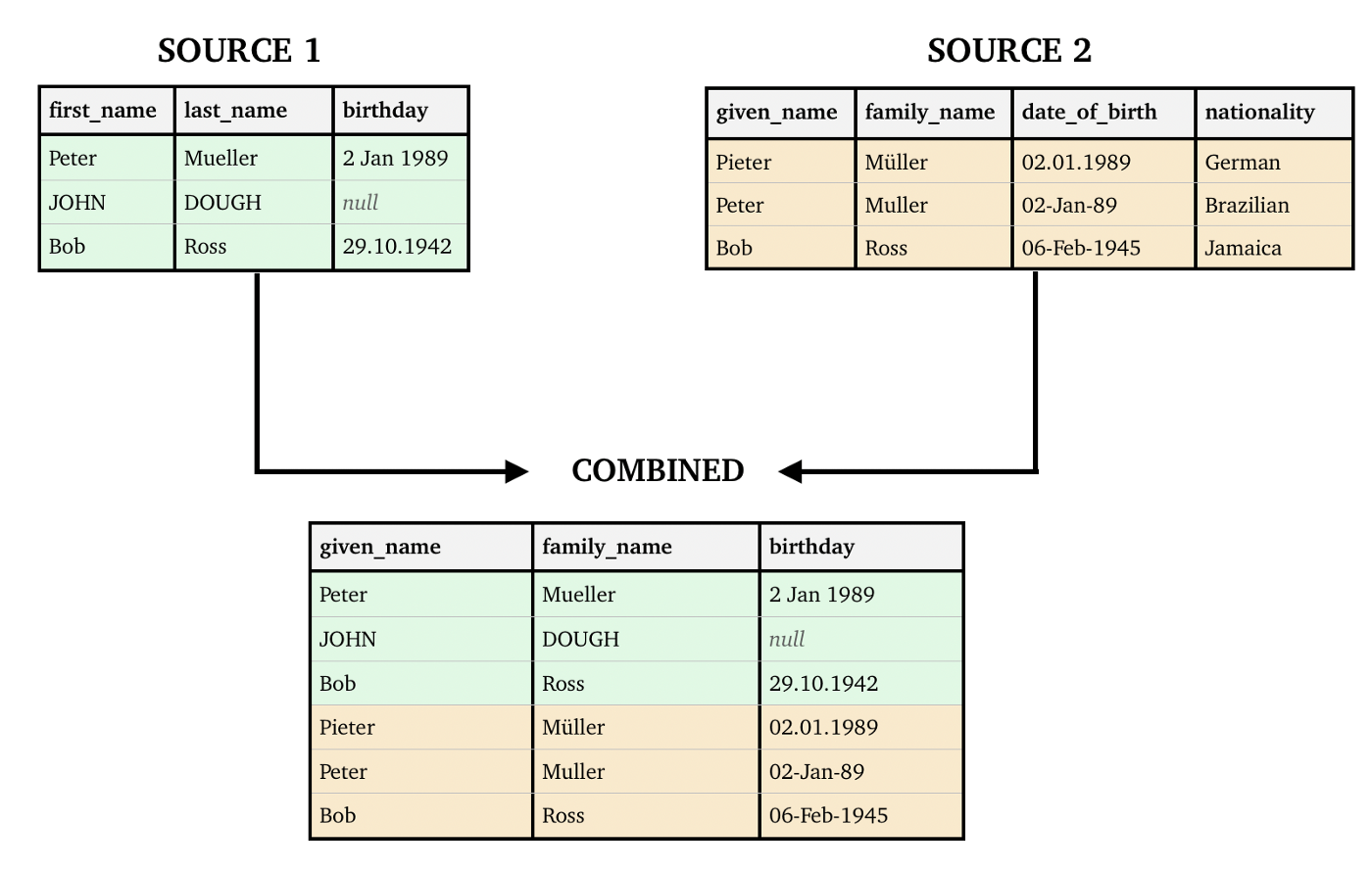
Combining multiple sources into a single schema
Clean
The second step is making sure that the data is clean and in the same format. Each data source might require different actions in order to reach a common schema but all data must pass through the same cleaning steps; thus, we perform it after combining.
One of the first things to check is whether the data has the same encoding. Not only do we want to make sure that we don’t see odd ’ characters but also that languages conform to a common translation. A typical choice is converting everything to ASCII. Doing so, Müller and Muller might then become the same. But what about Mueller? Moreover, case isSuES should also be avoided by either uppercasing or lowercasing everything. And what about languages that do not even use the latin alphabet?
Take a look below at the simplistic example for some of these steps, that tackles standardization for characters of the German language using pandas and a dictionary that defines the rules for conversion.
import pandas as pdde_mapping = {'Ü': 'U', 'Ä': 'A', 'Ö': 'O', 'ß': 'SS'} trans_table = ''.join(de_mapping.keys()).maketrans(de_mapping) df = pd.DataFrame({'family_name': ['Muller', 'Müller', 'Mueller']}) df['cleaned_family_name'] = df['family_name'].str.upper() df['cleaned_family_name'] = df['cleaned_family_name'].str.translate(trans_table)
One must also pay attention to whether the cleaning steps should be done in a certain order. For example, the difference between the german words schon (already) and schön (beautiful) would be lost if converting ö to o, and this could be a relevant loss of information in certain situations. Dates can also be tricky — they can not only be stored under different types, e.g. integer or string, but they also have different formats and precision.
Block
Trying to find all possible matches is a computationally expensive process. Computing all the pairs has n² complexity in both time and space, which is very expensive when dealing with millions of records. For example, a dataset of only 1,000 rows would yield 499,500 possible combinations! In order to optimise, we want to only save good potential pairs using a limited number of columns and computations. This is known as blocking. The problem becomes then choosing the right rules such that as many possible matches are found.
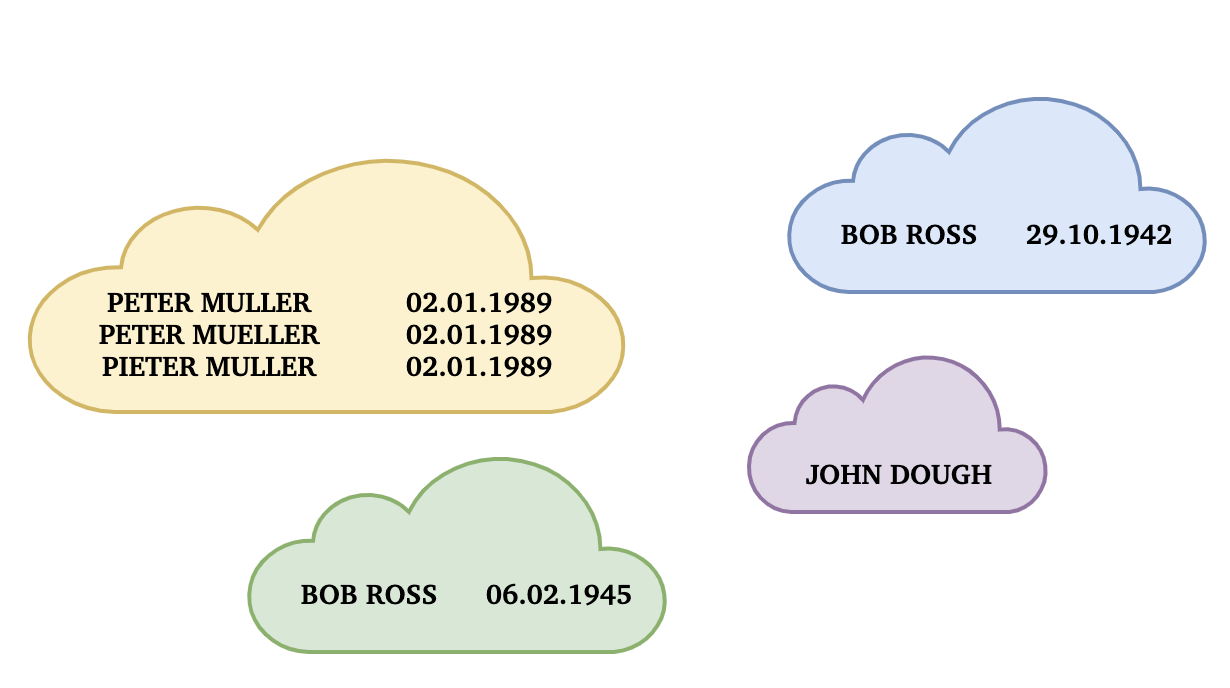
Following the same example, let’s try blocking on some simple rules. Creating possible links between people with the same last name correctly omits pairs such as MUELLER and ROSS. However, one might also notice some downsides: MULLER and MUELLER would not be paired. So, let’s add another rule — same birthday. Beware that blocking will be done on the same family name or the same birthday. See below how these rules successfully block our Peter Muller (-like) entries while omitting pairs such as John Dough and Bob Ross. Note how, even though both rules are satisfied in the case of PIETER MULLER/PETER MULLER pair, a single row is produced.
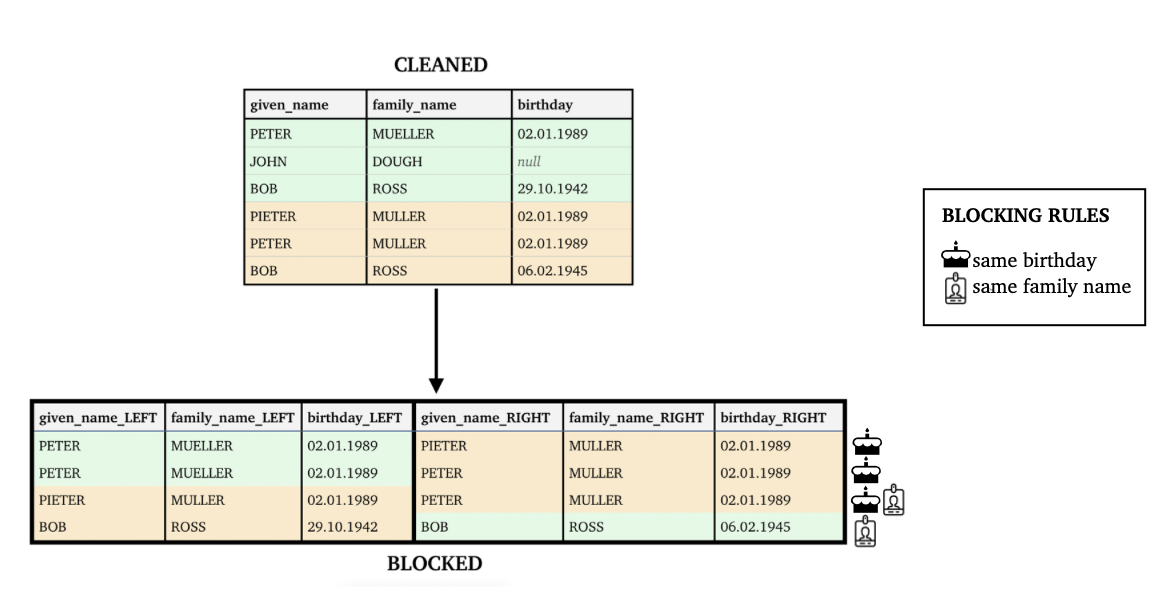
Blocking pairs up records based on carefully selected blocking rules
In practice, the rules typically rely on more complex logic. Good blocking requires finding the right balance of relaxed yet effective rules. For example, exact name matches are likely to miss typos or errors in translation. In such cases, one could try fuzzy matching or phonetic algorithms like soundex. We’ll talk about this and more in our next post.
Featurize
This is the step where data scientists and machine learning experts can finally use their creativity in finding the appropriate features to entity resolve. With possible edges created, we now need reliable ways to measure the similarity of the entities. Since we are dealing with string columns, we could use string similarity metrics such as Levenshtein or Jaccard distance.
The example below contains an example of using Jellyfish to calculate the Levenshtein distance between two names. In order to increase interpretability and comparability, the next step converts the distance into a similarity metric. To do that, the distance is divided by the maximum length of the two compared strings, then subtracted from 1.
import pandas as pd from jellyfish import levenshtein_distance def normalized_levenshtein(name_left, name_right): distance = levenshtein_distance(name_left, name_right) return 1 - distance / max(len(name_left), len(name_right))df = pd.DataFrame( {'name_left': ['PIETER MUELLER'], 'name_right': ['PETER MULLER']} ) df['levenshtein_full_name'] = df.apply( lambda x: normalized_levenshtein(x.name_left, x.name_right), axis=1)
An interesting example is when dealing with long(er) strings, such as Peter Mueller and Mueller Peter. Simply using a string similarity metric would result in a bad score when they are obviously the same (to us). Here, sorting the words could help. However, the same tactic might not be as useful for addresses. Simply because there are missing parts of the addresses does not mean the records are different; there might still be a lot in common! One could try splitting the address into components and computing the intersection.

Names should be matched even when written in a different order
A more advanced approach involves using word embeddings such as BERT or word2vec. These help by capturing correlations and hidden patterns we would otherwise miss. Continuing with our example, let’s stick to simple metrics. We compute as features the Levenshtein similarity of the full name and exact match of the birth date. Being numerical features, they would also suit well with state of the art models in the next step.

Featurization provides more accurate metrics for record similarities
Match
Tightly connected to the previously chosen features, you can now either use specific rules and/or leave it to a model to classify the pairs. With sufficiently clean data, rules might correctly label the vast majority of the data. In our example, choosing pairs with the Levenshtein similarity of the first name above 0.9 would only match our first PETER MUELLER/MULLER pair and ignore the other two possible combinations. This would be too restrictive if we would like to also match PETER MUELLER/PIETER MULLER or PIETER/PETER MULLER. Moreover, observe how not using the exact birthday in the matching process would lead our last pair to also be matched, even though they cannot be the same person — they just have the same full name. Rules are easy to create but tricky to perfect. For the purpose of this example, let’s choose a Levensthein similarity >= 0.85 AND exact birthday = 1. Therefore, in the end we will obtain four clusters.
The output of Entity Resolution contains clusters of records
A model could ease the process by implicitly finding the correct rules to match records. Neural networks have shown great potential in NLP tasks in the recent years and are known to do exactly this. However, such a black box model has little explainability and is hard to justify to the business that would like to know why records were matched. One could instead use a supervised model such as Random Forest or even attempt unsupervised techniques such as the Expectation-Maximization algorithm. Good data and model tuning remain furthermore of high importance.
Whichever path is chosen, iterating the model remains a task closely tied to business goals. Some might require that the pipeline has high confidence (low number of false positives), others might require returning every possibility (low number of false negatives); both would be of course ideal. Evaluating the performance can be done in various ways. We have hinted on using the confusion matrix, however this has its limitations. We’ll go over other metrics and their pros and cons in an upcoming blog post.
Conclusion
We have briefly presented Entity Resolution and its steps. Data needs to be combined through a single schema but also cleaned and formatted. Matching needs to be done in a smart way to avoid unnecessary computations but also thoroughly to maintain good performance. Both business knowledge and clever choices are critical. We followed the resolution of Peter Muller throughout all the phases and the challenges faced. Yet there are still points to cover at each step. How to be resilient when input data sources change schema? How to properly handle data in multiple languages? How to keep track of clusters over time? Stay tuned for our future blog posts in which we tackle such questions in more detail :]
This article was written by Radu Jica and Bianca Stancu.
